As system students of 90s, we remember that the classic distributed system course usually had strong assumptions on heterogeneity of nodes' geography and configurations (regarding both software and hardware). Many universities used Tanebaum's classic textbooks, and the distributed algorithms taught in the classes mostly dealt with fault tolerant, consistency and focused on a point-to-point communication paradigm. These algorithms are still very valuable and being will used in the various system. However, the industry force shifted the paradigm to a more centralized, more homogeneous, richer bandwidth-based high performance computer clusters. Or using more widely known and hyped name, we call it clouds computing.
To catch up the trend, we introduced the big data framework into DSP course (check my previous blog) in 2014 and 2015. We chose to use Hadoop in 2014 course and "upgraded" to Spark in 2015, but the questions remain more or less the same. Compared with the previous example I introduced, this set of exercises turned out to be a big success. So what did we actually asked the students to do?
I. Finding A Needle in A Haystack
The power of big data framework is fast processing and analyzing huge data sets by taking advantage of the computational and storage resources in high performance computer clusters. In the question set, we gave the students a date set of a very simple structure -- just one double number per line. The data set contains 10 billions lines. For generating data, I used Weibull and Gaussian mixture model. Technically, this is not really "Big Data", but I think it is pretty enough for the students to grasp the idea. We asked the students to provide the following statistics of the data set.
By the way, we did not allow the students to use the default functions provided in the framework. We asked them to implement the functions by themselves using map-reduce paradigm (see figure blow). Some students did complain about reinventing wheels. But in my opinion, as a system engineer, you should know what happens behind the scene. However, to help the student start, I provided the example code to calculate the minimum value.
For getting the maximum, it is very easy by simply tweaking my example code. Map-reduce is very good at handling data-parallel computation. A data set is divided into chunks then distributed on multiple nodes then processes in parallel. The minimum of the minimums (of all the chunks) is the minimum of the whole data set. The same applies to the maximum. However, the students need pay a bit more attention when dealing with mean value, since the mean of all mean values is simply not the mean value of the whole data set. It turned out some students did make this silly mistake.
The variance value needs even more thinking. We know there are (at least) two ways to calculate variance.
The first method is familiar to almost everyone, and indeed most students chose to use it. However, it needs to iterate the data set twice. Whereas for the second method, you only need to iterate the data set once. It is worth noting that iteration used to be expensive, especially for Hadoop in the early days. Though Spark has improved quite a lot, scheduling still contributes a significant time overhead in the calculations. So reducing the number of iterations is still a good idea when dealing with big data.
II. Handling Order Statistic
Things turned to be extremely interesting when the students started calculating the median value. Similar to the mean value, median of the medians are not the median of the whole data set. Median is one of the order statistic like Quantile, Percentile, Decile and etc. By definition, the median separates a data set into two equal parts. Technically, you need sort the data from the smallest to the largest and choose the middle one (break the tie if necessary). However, such conventional operation of getting median is not really suitable when dealing with large data sets.
Can you image sorting a data set of hundreds of GB or TB or even PB? First, you simply do not have enough memory to do that on one node. Second, you will introduce huge traffic if you try to do that in distributed way. Well, some of the students did try to sort the data, then quickly got frustrated. At this point, they realized they need to think differently in the context of big data. What's more, they also realized that the map-reduce may not be as straightforward as they thought.
The students eventually came up various solutions which can be categorized as below:
Median of medians - it is an approximation algorithm which gives a quick estimate of the median. But you still need sort the data set at least partially and only get an estimate, which is not good. For the algorithmic details, please check the [wiki page].
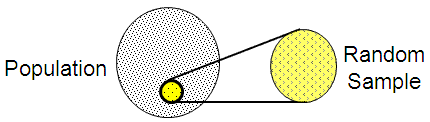
Random sampling - this method tries to get a random sample from the data set and use the median of the sample to estimate the median of the population. This method may work well on certain data which follow well-defined distributions like Gaussian, uniform and etc. However, let's imagine a data set wherein the first half numbers are 1, the latter half are 100, and the actual median is 57. Then the random sampling method is doomed to fail with high probability.
Binary search - if we think about the definition of median, it is not difficult to notice the median is bigger than 50% of the data and smaller then the other 50%, because this is simply its definition. So we can just randomly guess a number and check how many data fall on the left (i.e. smaller than the guessed number), and how many data fall on the right (i.e. bigger than the guessed number). Then we can know whether we under- or over-estimated the median. We can narrow down the scope by iterating this search until we find the true median.

Buckets/Histogram method - Binary search is already very close to the correct solution. But let me ask another question - how many iterations does binary search need to find the actual median? Easy, it is just $\log_2(N)$ where $N$ is the size of the data set. For those students who successfully reached the binary search solution, I asked them - "Can you further improve the performance by reducing the number of iterations?"
Of course you can! In some sense, the binary search uses two buckets and count the number of data in each bucket. We can certainly use more buckets and apply the same algorithmic logic here, then the narrow down the range where the median falls much faster. E.g., if we use $b$ buckets, then we only need $\log_b(N)$ iterations. So feel free to choose $b = 1000$ or $b = 10000$, the introduced traffic overhead is negligible. Such method also has another name - histogram method. The figure blow sketches the crude idea, and there are some other materials on the Internet talking about this method. E.g., this YouTube video [here].

III. Do the Students Like This Exercise?
It turned out this exercise set was extremely successful. From teaching perspective, the exercise only uses simple statistics which every student can understand with very mathematical background. The wonderful part of the exercise is that all these statistics look similar and straightforward in the mathematical sense. However, from (data) engineering perspective, you need treat them completely differently. The exercise set reminds the student that porting the classic algorithms into big data context may not be as straightforward as they originally thought.
In the actual teaching, all the students solved min and max without any problem. Surprisingly, over 60% of the students still chose the slower way to calculate the variance. For median, it is even more striking. For these two years, only three students independently came up histogram method without any help from me. About the students' attitudes, in general, they like the question set very much, the main reason of which, I believe is because their strong curiosity on the hyped big data.
Read this series: The Spherical Cow in System Science - Part I, Part II, Part III
To catch up the trend, we introduced the big data framework into DSP course (check my previous blog) in 2014 and 2015. We chose to use Hadoop in 2014 course and "upgraded" to Spark in 2015, but the questions remain more or less the same. Compared with the previous example I introduced, this set of exercises turned out to be a big success. So what did we actually asked the students to do?
I. Finding A Needle in A Haystack
The power of big data framework is fast processing and analyzing huge data sets by taking advantage of the computational and storage resources in high performance computer clusters. In the question set, we gave the students a date set of a very simple structure -- just one double number per line. The data set contains 10 billions lines. For generating data, I used Weibull and Gaussian mixture model. Technically, this is not really "Big Data", but I think it is pretty enough for the students to grasp the idea. We asked the students to provide the following statistics of the data set.
- Minimum value
- Maximum value
- Mean value
- Variance value
- Median value
By the way, we did not allow the students to use the default functions provided in the framework. We asked them to implement the functions by themselves using map-reduce paradigm (see figure blow). Some students did complain about reinventing wheels. But in my opinion, as a system engineer, you should know what happens behind the scene. However, to help the student start, I provided the example code to calculate the minimum value.
 |
| A figure summarizes the map-reduce-based data-parallel computing paradigm. |
The variance value needs even more thinking. We know there are (at least) two ways to calculate variance.
- $Var(X) = E[(X - \mu)^2]$
- $Var(X) = E[X^2] - (E[X])^2$
The first method is familiar to almost everyone, and indeed most students chose to use it. However, it needs to iterate the data set twice. Whereas for the second method, you only need to iterate the data set once. It is worth noting that iteration used to be expensive, especially for Hadoop in the early days. Though Spark has improved quite a lot, scheduling still contributes a significant time overhead in the calculations. So reducing the number of iterations is still a good idea when dealing with big data.
II. Handling Order Statistic
Things turned to be extremely interesting when the students started calculating the median value. Similar to the mean value, median of the medians are not the median of the whole data set. Median is one of the order statistic like Quantile, Percentile, Decile and etc. By definition, the median separates a data set into two equal parts. Technically, you need sort the data from the smallest to the largest and choose the middle one (break the tie if necessary). However, such conventional operation of getting median is not really suitable when dealing with large data sets.
Can you image sorting a data set of hundreds of GB or TB or even PB? First, you simply do not have enough memory to do that on one node. Second, you will introduce huge traffic if you try to do that in distributed way. Well, some of the students did try to sort the data, then quickly got frustrated. At this point, they realized they need to think differently in the context of big data. What's more, they also realized that the map-reduce may not be as straightforward as they thought.
The students eventually came up various solutions which can be categorized as below:
Median of medians - it is an approximation algorithm which gives a quick estimate of the median. But you still need sort the data set at least partially and only get an estimate, which is not good. For the algorithmic details, please check the [wiki page].
Random sampling - this method tries to get a random sample from the data set and use the median of the sample to estimate the median of the population. This method may work well on certain data which follow well-defined distributions like Gaussian, uniform and etc. However, let's imagine a data set wherein the first half numbers are 1, the latter half are 100, and the actual median is 57. Then the random sampling method is doomed to fail with high probability.
Binary search - if we think about the definition of median, it is not difficult to notice the median is bigger than 50% of the data and smaller then the other 50%, because this is simply its definition. So we can just randomly guess a number and check how many data fall on the left (i.e. smaller than the guessed number), and how many data fall on the right (i.e. bigger than the guessed number). Then we can know whether we under- or over-estimated the median. We can narrow down the scope by iterating this search until we find the true median.
Buckets/Histogram method - Binary search is already very close to the correct solution. But let me ask another question - how many iterations does binary search need to find the actual median? Easy, it is just $\log_2(N)$ where $N$ is the size of the data set. For those students who successfully reached the binary search solution, I asked them - "Can you further improve the performance by reducing the number of iterations?"
Of course you can! In some sense, the binary search uses two buckets and count the number of data in each bucket. We can certainly use more buckets and apply the same algorithmic logic here, then the narrow down the range where the median falls much faster. E.g., if we use $b$ buckets, then we only need $\log_b(N)$ iterations. So feel free to choose $b = 1000$ or $b = 10000$, the introduced traffic overhead is negligible. Such method also has another name - histogram method. The figure blow sketches the crude idea, and there are some other materials on the Internet talking about this method. E.g., this YouTube video [here].
III. Do the Students Like This Exercise?
It turned out this exercise set was extremely successful. From teaching perspective, the exercise only uses simple statistics which every student can understand with very mathematical background. The wonderful part of the exercise is that all these statistics look similar and straightforward in the mathematical sense. However, from (data) engineering perspective, you need treat them completely differently. The exercise set reminds the student that porting the classic algorithms into big data context may not be as straightforward as they originally thought.
In the actual teaching, all the students solved min and max without any problem. Surprisingly, over 60% of the students still chose the slower way to calculate the variance. For median, it is even more striking. For these two years, only three students independently came up histogram method without any help from me. About the students' attitudes, in general, they like the question set very much, the main reason of which, I believe is because their strong curiosity on the hyped big data.
Read this series: The Spherical Cow in System Science - Part I, Part II, Part III
No comments:
Post a Comment